Fine-Tuning CLIP Models
Enhance your CLIP model by performing fine-tuning for image classification
In the swiftly advancing domain of artificial intelligence, the role of CLIP (Contrastive Language-Image Pre-training) models in computer vision has been both significant and revolutionary. Following our in-depth discussion on the architecture of CLIP models in the previous article, we now turn our attention to how one can fine-tune such sophisticated models.
Before diving in, if you need help, guidance, or want to ask questions, join our Community and a member of the Marqo team will be there to help.
1. What is CLIP?
Before diving into the specifics of training and fine-tuning, let’s revisit the key concepts behind CLIP models. Developed by OpenAI, CLIP represents a notable breakthrough in combining computer vision and natural language processing. It utilizes a large dataset of images paired with textual descriptions to train a model capable of understanding and correlating visual and textual information.
The fundamental innovation of CLIP lies in its ability to process both images and text into a shared embedding space. This is achieved through two main components: an image encoder and a text encoder. The image encoder converts images into embeddings, while the text encoder performs the same function for text. These embeddings are then aligned using contrastive learning, which brings the embeddings of matching image-text pairs closer together and pushes apart those of non-matching pairs.
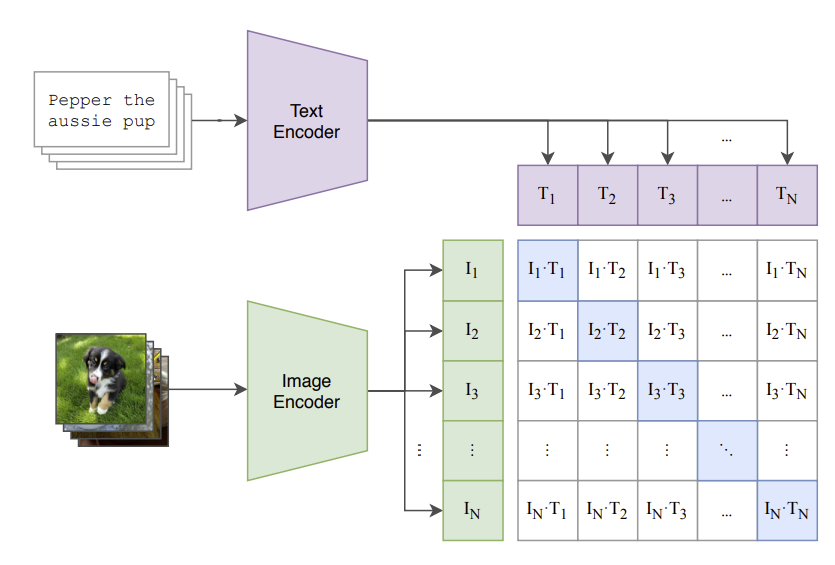
CLIP’s capacity to learn from extensive image-text pairs empowers it to perform a variety of tasks without needing task-specific fine-tuning. This versatility, coupled with its strong performance in zero-shot learning scenarios, makes CLIP an attractive choice for a myriad of applications, including image classification and object detection.
Let’s take a look at how we can fine-tune our own CLIP model for image classification!
2. Fine-Tuning CLIP Models
In this section, we will discuss how you can leverage Hugging Face’s datasets to download and process image classification datasets and then use them to fine-tune a pre-trained CLIP Model with pytorch.
For this article, we will be using Google Colab (it’s free!). If you are new to Google Colab, you can follow this guide on getting set up - it’s super easy! For this module, you can find the notebook on Google Colab here or on GitHub here. As always, if you face any issues, join our Slack Community and a member of our team will help!
For this article, you will want to use the GPU features on Google Colab. We’d recommend changing your runtime on Google Colab to T4 GPU. This article explains how to do this.
Install and Import Relevant Libraries
We first install relevant modules:
!pip install openai-clip
!pip install datasets
!pip install torch
!pip install tqdm
We will be using openai-clip to define our base CLIP model and utilising datasets provided by Hugging Face. The library torch will be used to facilitate model loading, device management, tensor manipulation, and inference. Finally, tqdm is used to track the progress of the fine-tuning.
Now we've installed the libraries needed to fine-tune, we must obtain a dataset to perform this fine-tuning.
Load a Dataset
To perform fine-tuning, we will use a small image classification dataset. We’ll use the ceyda/fashion-products-small dataset which is a collection of fashion products.
from datasets import load_dataset
# Load the dataset
ds = load_dataset('ceyda/fashion-products-small')
Let's take a look at the features inside this dataset by printing ds. This outputs:
DatasetDict({
train: Dataset({
features: ['filename', 'link', 'id', 'masterCategory', 'gender', 'subCategory', 'image'],
num_rows: 42700
})
})
We see that we have filename, link, id, masterCategory, gender, subCategory and image. Let's print the first example from this dataset to see what these features mean:
entry = ds['train'][0]
entry
This outputs:
{'filename': '15970.jpg',
'link': 'http://assets.myntassets.com/v1/images/style/properties/7a5b82d1372a7a5c6de67ae7a314fd91_images.jpg',
'id': '15970',
'masterCategory': 'Apparel',
'gender': 'Men',
'subCategory': 'Topwear',
'image': <PIL.JpegImagePlugin.JpegImageFile image mode=RGB size=384x512>}
Thus, the features of the dataset are as follows:
- filename: this is the filename of the image, indicating that the image is stored or identified with this name.
- link: this is a URL link to the actual image file, which is hosted online. This link can be used to view or download the image.
- id: this is a unique identifier for the image, which can be used to reference this specific item within the dataset.
- masterCategory: this indicates the broad category under which this product falls.
- gender: this specifies the intended gender for the product, in this case, men's clothing.
- subCategory: this is a more specific category within the master category. "Topwear" indicates that the product is an item of clothing worn on the upper body, such as a shirt, t-shirt, or jacket.
- image: this is a PIL (Python Imaging Library) image object, which allows for image manipulation and processing. It specifies the image mode (RGB, meaning it has red, green, and blue color channels) and the image size (384 pixels wide by 512 pixels tall).
Cool, let’s look at the image!
image = entry['image']
image

As expected, it's an item of men's topwear.
We can see that the data itself is comprised of a train dataset, so we will define our dataset as this.
dataset = ds['train']
Awesome, so now we've seen what our dataset looks like, it's time to load our CLIP model and perform preprocessing.
Load CLIP Model and Preprocessing
The CLIP model (ViT-B/32) and its preprocessing function are loaded. The model is moved to the appropriate device (GPU if available, otherwise CPU).
import clip
import torch
# OpenAI CLIP model and preprocessing
model, preprocess = clip.load("ViT-B/32", jit=False)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
Let's take a look at how well our base CLIP model performs image classification on this dataset.
This code uses the CLIP model to classify three example images from our dataset by comparing their visual features with textual descriptions of subcategories. It processes and normalizes the features of the images and subcategory texts, calculates their similarity, and predicts the subcategory for each image. Finally, it visualizes the images alongside their predicted and actual subcategories in a plot.
import matplotlib.pyplot as plt
# Select indices for three example images
indices = [0, 2, 10]
# Get the list of possible subcategories from the dataset
subcategories = list(set(example['subCategory'] for example in dataset))
# Preprocess the text descriptions for each subcategory
text_inputs = torch.cat([clip.tokenize(f"a photo of {c}") for c in subcategories]).to(device)
# Create a figure with subplots
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# Loop through the indices and process each image
for i, idx in enumerate(indices):
# Select an example image from the dataset
example = dataset[idx]
image = example['image']
subcategory = example['subCategory']
# Preprocess the image
image_input = preprocess(image).unsqueeze(0).to(device)
# Calculate image and text features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# Normalize the features
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
# Calculate similarity between image and text features
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(1)
# Display the image in the subplot
axes[i].imshow(image)
axes[i].set_title(f"Predicted: {subcategories[indices[0]]}, Actual: {subcategory}")
axes[i].axis('off')
# Show the plot
plt.tight_layout()
plt.show()
This outputs the following:

As we can see for the three images, our base CLIP model does not perform very well. It only identifies one of the three images correctly.
Let's set up the process for fine-tuning our CLIP model to improve these predictions.
Processing the Dataset
First, we must split our dataset into training and validation sets. This step is crucial because it allows us to evaluate the performance of our machine learning model on unseen data, ensuring that the model generalizes well to new, real-world data rather than just the data it was trained on.
We take 80% of the original dataset to train our model and the remaining 20% as the validation data.
from torch.utils.data import random_split
# Split dataset into training and validation sets
train_size = int(0.8 * len(dataset))
val_size = len(dataset) - train_size
train_dataset, val_dataset = random_split(dataset, [train_size, val_size])
Next, we create a custom dataset class:
from torchvision import transforms
from torch.utils.data import Dataset
# Define a custom dataset class
class FashionDataset(Dataset):
def __init__(self, data):
self.data = data
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
])
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
image = item['image']
subcategory = item['subCategory']
label = subcategories.index(subcategory)
return self.transform(image), label
Let's break this down:
- __init__ method: initializes the dataset object with data and sets up a series of transformations to preprocess the images. The transformations include resizing the images to 224x224 pixels, converting them to tensors, and normalizing them with specific mean and standard deviation values.
- __len__ method: returns the number of samples in the dataset.
- __getitem__ method: retrieves an image and its corresponding subcategory from the dataset. The image is transformed using the predefined transformations, and the subcategory is converted to a label by finding its index in the subcategories list.
Next, we create DataLoaders:
from torch.utils.data import DataLoader
# Create DataLoader for training and validation sets
train_loader = DataLoader(FashionDataset(train_dataset), batch_size=32, shuffle=True)
val_loader = DataLoader(FashionDataset(val_dataset), batch_size=32, shuffle=False)
Here,
- train_loader: A DataLoader for the training set, with a batch size of 32 and shuffling enabled to randomize the order of samples.
- val_loader: A DataLoader for the validation set, with a batch size of 32 and shuffling disabled to maintain the order of samples.
Next, we modify the model for fine-tuning:
import torch.nn as nn
# Modify the model to include a classifier for subcategories
class CLIPFineTuner(nn.Module):
def __init__(self, model, num_classes):
super(CLIPFineTuner, self).__init__()
self.model = model
self.classifier = nn.Linear(model.visual.output_dim, num_classes)
def forward(self, x):
with torch.no_grad():
features = self.model.encode_image(x).float() # Convert to float32
return self.classifier(features)
Here,
- __init__ method: Initializes the fine-tuning model with a base CLIP model and a new linear classifier for the subcategories. The linear layer has num_classes output units, corresponding to the number of subcategories.
- forward method: Passes the input images through the base CLIP model to extract features (without updating the base model's weights) and then through the new classifier to predict the subcategory.
Finally, we instantiate the fine-tuning model:
num_classes = len(subcategories)
model_ft = CLIPFineTuner(model, num_classes).to(device)
Here,
- num_classes: The number of unique subcategories in the dataset.
- model_ft: An instance of the CLIPFineTuner class, set up for fine-tuning on the subcategory classification task, and moved to the specified device (CPU or GPU).
Amazing! We've set up everything we need to perform fine-tuning! Let's now define our loss function and optimizer.
Define Loss Function and Optimizer
We define as follows:
import torch.optim as optim
# Define the loss function and optimizer
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model_ft.classifier.parameters(), lr=1e-4)
Here,
- criterion: The loss function used is Cross-Entropy Loss, which is suitable for multi-class classification tasks.
- optimizer: The optimizer used is Adam, applied only to the parameters of the classifier layer (model_ft.classifier.parameters()) with a learning rate of 0.0001.
Great, now we set up the fine-tuning!
Fine-Tuning CLIP Model
We are now in a position to perform our fine-tuning. Let's break down the code in the training loop below.
Training:
- num_epochs: Specifies the number of epochs (iterations over the entire training dataset).
- Training mode: The model is set to training mode using model_ft.train().
- Progress bar: A progress bar (tqdm) is used to track the progress of the training loop, displaying the current epoch and running loss.
-
Training steps:
-
For each batch of images and labels from train_loader:
- Move the images and labels to the specified device (CPU or GPU).
- Zero the gradients using optimizer.zero_grad().
- Forward pass: Compute the model's outputs.
- Compute the loss using criterion.
- Backward pass: Compute gradients using loss.backward().
- Update the model parameters using optimizer.step().
- Update the running loss.
- Update the progress bar description with the average loss for the epoch.
-
For each batch of images and labels from train_loader:
- After each epoch, the average loss for the epoch is printed.
Validation:
- Evaluation mode: The model is set to evaluation mode using model_ft.eval().
-
Accuracy calculation:
- Disable gradient computation with torch.no_grad().
-
For each batch of images and labels from val_loader:
- Move the images and labels to the specified device.
- Forward pass: Compute the model's outputs.
- Get the predicted labels by finding the class with the highest score using torch.max.
- Update the total number of labels and the count of correct predictions.
- Calculate and print the validation accuracy as a percentage.
Save the Fine-Tuned Model: The state dictionary of the fine-tuned model is saved to a file named 'clip_finetuned.pth'.
Here’s the full code:
from tqdm import tqdm
# Number of epochs for training
num_epochs = 5
# Training loop
for epoch in range(num_epochs):
model_ft.train() # Set the model to training mode
running_loss = 0.0 # Initialize running loss for the current epoch
pbar = tqdm(train_loader, desc=f"Epoch {epoch+1}/{num_epochs}, Loss: 0.0000") # Initialize progress bar
for images, labels in pbar:
images, labels = images.to(device), labels.to(device) # Move images and labels to the device (GPU or CPU)
optimizer.zero_grad() # Clear the gradients of all optimized variables
outputs = model_ft(images) # Forward pass: compute predicted outputs by passing inputs to the model
loss = criterion(outputs, labels) # Calculate the loss
loss.backward() # Backward pass: compute gradient of the loss with respect to model parameters
optimizer.step() # Perform a single optimization step (parameter update)
running_loss += loss.item() # Update running loss
pbar.set_description(f"Epoch {epoch+1}/{num_epochs}, Loss: {running_loss/len(train_loader):.4f}") # Update progress bar with current loss
print(f'Epoch [{epoch+1}/{num_epochs}], Loss: {running_loss/len(train_loader):.4f}') # Print average loss for the epoch
# Validation
model_ft.eval() # Set the model to evaluation mode
correct = 0 # Initialize correct predictions counter
total = 0 # Initialize total samples counter
with torch.no_grad(): # Disable gradient calculation for validation
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device) # Move images and labels to the device
outputs = model_ft(images) # Forward pass: compute predicted outputs by passing inputs to the model
_, predicted = torch.max(outputs.data, 1) # Get the class label with the highest probability
total += labels.size(0) # Update total samples
correct += (predicted == labels).sum().item() # Update correct predictions
print(f'Validation Accuracy: {100 * correct / total}%') # Print validation accuracy for the epoch
# Save the fine-tuned model
torch.save(model_ft.state_dict(), 'clip_finetuned.pth') # Save the model's state dictionary
Amazing! Each epoch takes around 3 minutes to run. Since we have 5 epochs, this code takes roughly 15 minutes so go grab yourself a cup of tea ☕️ and come back to see the magic of fine-tuning!
Here's a screenshot of the results we get once fine-tuning is complete. Note, you may get different results when running the code yourself.
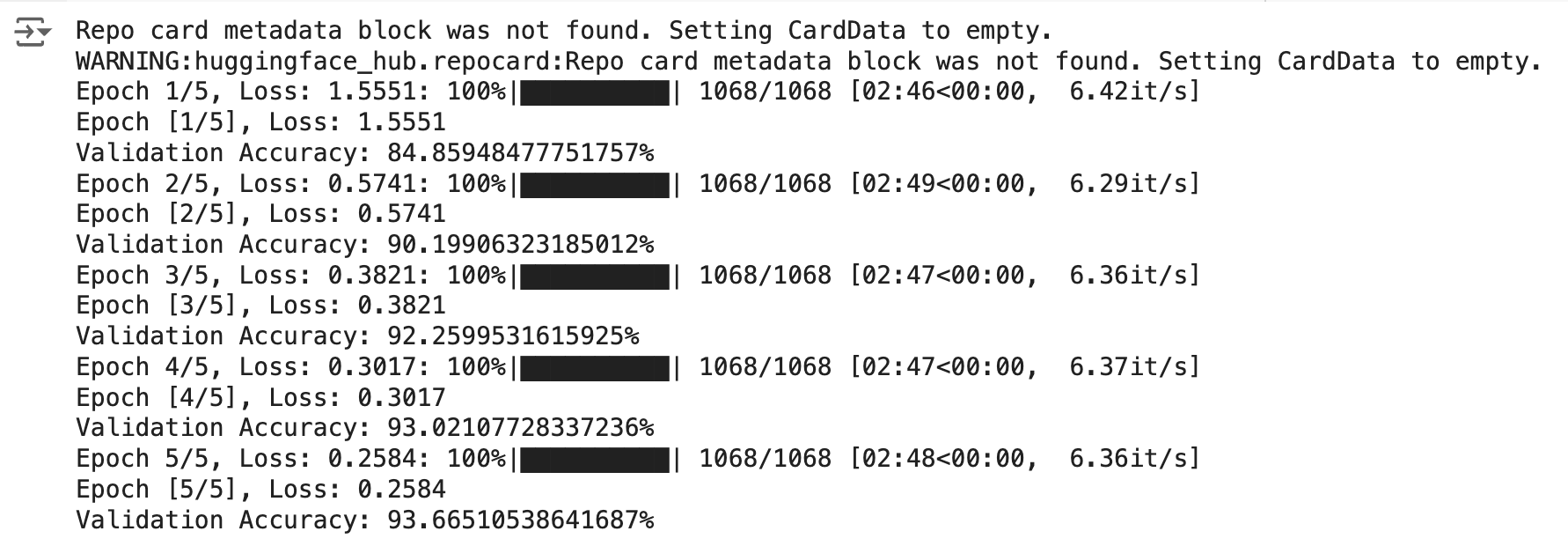
As you can see, the fine-tuning process is successful, with the model showing significant improvements in both training loss and validation accuracy across the epochs. The final validation accuracy of 93.67% is a strong result, indicating that the model has effectively learned from the training data and is performing well on validation data. The gradual decrease in training loss and steady increase in validation accuracy reflect a well-conducted training process with no signs of overfitting or underfitting.
Amazing! Let's now take a look at how our new model performs on the same images we tested earlier.
import matplotlib.pyplot as plt
import torch
from torchvision import transforms
# Load the saved model weights
model_ft.load_state_dict(torch.load('clip_finetuned.pth'))
model_ft.eval() # Set the model to evaluation mode
# Define the indices for the three images
indices = [0, 2, 10]
# Preprocess the image
transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711))
])
# Create a figure with subplots
fig, axes = plt.subplots(1, 3, figsize=(15, 5))
# Loop through the indices and process each image
for i, idx in enumerate(indices):
# Get the image and label from the dataset
item = dataset[idx]
image = item['image']
true_label = item['subCategory']
# Transform the image
image_tensor = transform(image).unsqueeze(0).to(device) # Add batch dimension and move to device
# Perform inference
with torch.no_grad():
output = model_ft(image_tensor)
_, predicted_label_idx = torch.max(output, 1)
predicted_label = subcategories[predicted_label_idx.item()]
# Display the image in the subplot
axes[i].imshow(image)
axes[i].set_title(f'True label: {true_label}\nPredicted label: {predicted_label}')
axes[i].axis('off')
# Show the plot
plt.tight_layout()
plt.show()
This returns the following:

Super cool! Our newly fine-tuned CLIP model successfully predicts the labels for the three images!
Why don't you test out different images and settings to see if you can get even better results!
3. Conclusion
In this article, we successfully fine-tuned a CLIP model for image classification, demonstrating significant performance improvements. Starting with a pre-trained CLIP model, we utilized a fashion dataset and processed it to train the model effectively. Through careful dataset preparation, model modification, and training, we achieved high validation accuracy and improved predictions. This process highlights the power and versatility of CLIP models in adapting to specific tasks.
4. References
[1] A. Radford, et al. Learning Transferable Visual Models From Natural Language Supervision (2021)